How It Works
SignalPilot runs an 8-stage dbt workflow on every task: scan → load skills → validate → discover macros → research → spec → build → verify. The shape of the work is a plan → build → verify loop — the agent never writes SQL from intuition. It maps the project, researches the data, distills a written spec, builds only what the spec describes, then hands the result to two independent read-only verifier subagents that check structure and values. Fixes feed back into the spec and the loop repeats until every check passes.
The full workflow is defined by the dbt-workflow skill. Stages 1, 2, 3, and 8 always run. Stages 4–7 run only when the scan finds stubs to rewrite or models to build (or the task edits existing models).
01 — Scan the project
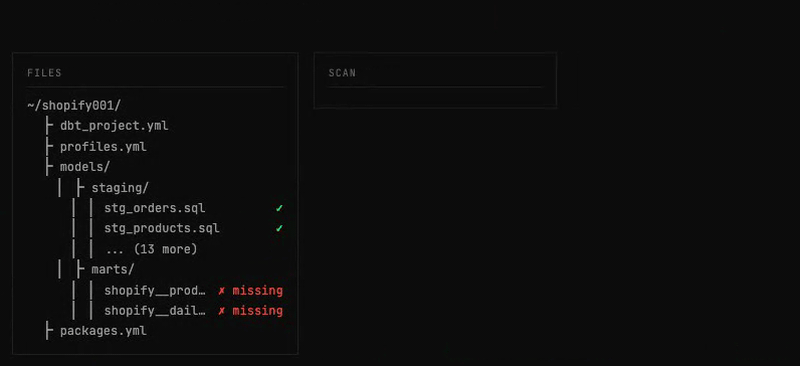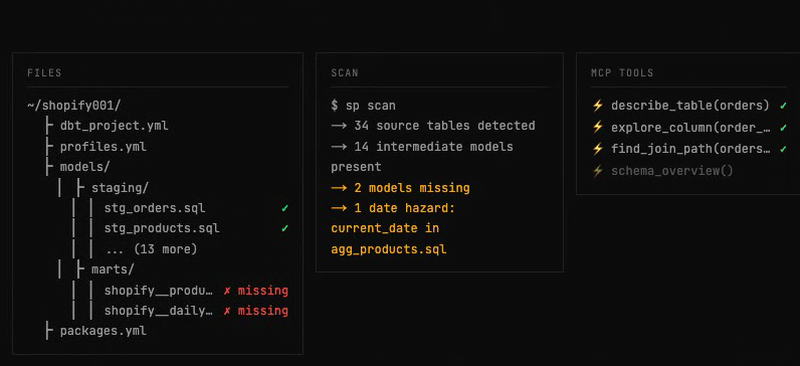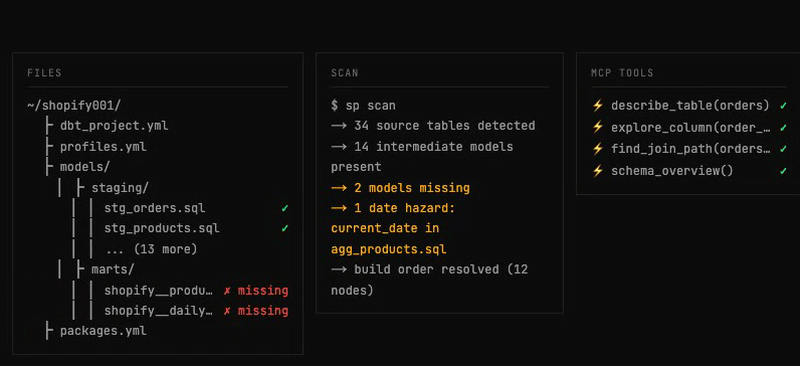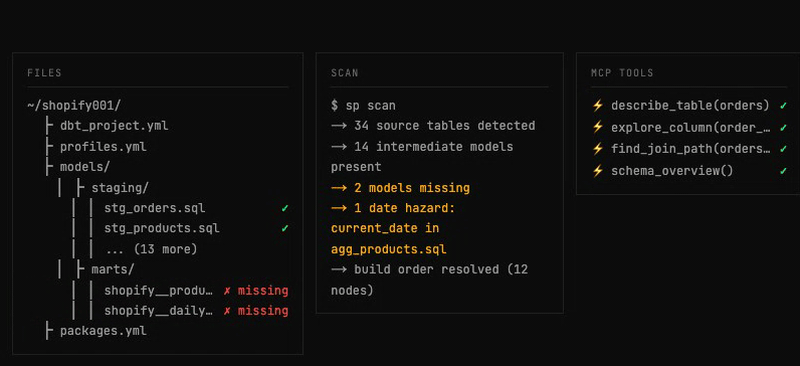
Before any work, the agent inventories everything the project requires.
- Before the scan,
get_knowledgeloads org/project conventions and prior research — these inform the work but never skip a stage. scan_project.pyreturns: models to build, stubs to rewrite, dependencies, required columns, sources, macros (with full definitions), andcurrent_date/now()hazards.- Schema MCP tools confirm the live picture:
list_tables,schema_overview,schema_statistics,get_relationships, andget_date_boundariesfor a data-driven date floor/ceiling. - The scan resolves build order across the DAG deterministically, then a task is created for each remaining stage.
02 — Load supporting skills
Rule-bearing skills load before writing and verifying — they govern both. Three always load: dbt-write (SQL writing rules), the database SQL skill (e.g. duckdb-sql, snowflake-sql), and a domain skill chosen by classifying the task and source-table names (one of domain-financial, domain-marketing, domain-product, domain-hr, domain-ecommerce, domain-media, domain-healthcare). Conditional skills load on trigger: dbt-testing (tests / unit_tests:), dbt-snapshots (SCD / snapshots/ dir), dbt-versioning (versions / versions: blocks).
03 — Validate and fix stale upstreams
validate_project.pyrunsdbt parse; structural errors are fixed before proceeding.- If the scan flagged
current_date/now()hazards in pre-existing models, those models are rebuilt now withdbt run --select <model>— they hold stale data that would poison every downstream row count. The knowledge base cannot fix already-materialized stale data.
04 — Discover project macros
For each project macro not yet used by a complete model, the agent reads its definition, identifies the column it produces (e.g. extract_hour(created_at) → hour_created_at), and records which models must include it. These macro-derived columns are extra output columns beyond the YML list, added during the build.
05 — Research the data
This is the evidence-gathering core of the plan phase. For each model the agent gathers five facts, all confirmed against live data — never assumed from YML.
- Driving table + JOIN strategy — the metric type is binding. COUNT/SUM metrics keep childless parents (drive FROM the parent, LEFT JOIN children); ratio/average/score metrics drop them (drive FROM the child aggregation, INNER JOIN the entity). This overrides the task's "aggregate X by Y" phrasing.
- Cardinalities —
query_databasewithCOUNT(*)andCOUNT(DISTINCT key)confirms grain;analyze_graintests candidate keys for uniqueness and fan-out. - Contract — the model's YML entry for column names, tests, and descriptions.
- Sibling patterns — sibling SQL and
dbt_packages/YML for JOIN types, CASE WHEN predicates, and categorical vocabulary. - Categorical values —
explore_column/SELECT DISTINCTon status/flag/type columns before writing any CASE WHEN.
Supporting research tools: explore_table, explore_columns, describe_table, schema_link, find_join_path, compare_join_types (preview INNER/LEFT/RIGHT/FULL row counts before committing to a JOIN), query_history, and search_knowledge.
06 — Write the technical spec
The knowledge-base skill loads and writes <project_dir>/technical_spec.md — a structured plan distilling Stage 5 research into per-model decisions on sources, joins, filters, expressions, and grain. Every model must carry all seven required fields before the stage can stop. The spec is the single input to the build and the single thing edited before any verification fix. If the spec already exists (a retry), the skill reads it and skips re-research.
07 — Write and build models
Implement SQL straight from the spec, then materialize only what was written.
map-columnsruns before each model, mapping upstream columns to the YML contract (MAPPED / UNMAPPED-INCLUDE / UNMAPPED-EXCLUDE).- YML column names are matched exactly; sibling JOIN/aggregation patterns and macro-derived columns (Stage 4) are applied; YML descriptions drive date boundaries and explicit transformation logic.
- Bug fixes are minimal edits — change only the broken expression, never rewrite a pre-existing file from scratch (that silently drops JOINs, filters, and aliases).
- Build with
dbt run --select <model1> <model2>— no+prefix (which would rebuild upstreams the agent did not write, destroying surrogate keys and FK relationships). A baredbt runis never used. - On failure, the
dbt-debuggingskill loads;dbt_error_parserturns raw dbt stderr into a structured fix. Supporting build-time tools:generate_sql_skeleton,validate_sql,explain_query,debug_cte_query,estimate_query_cost,check_budget.
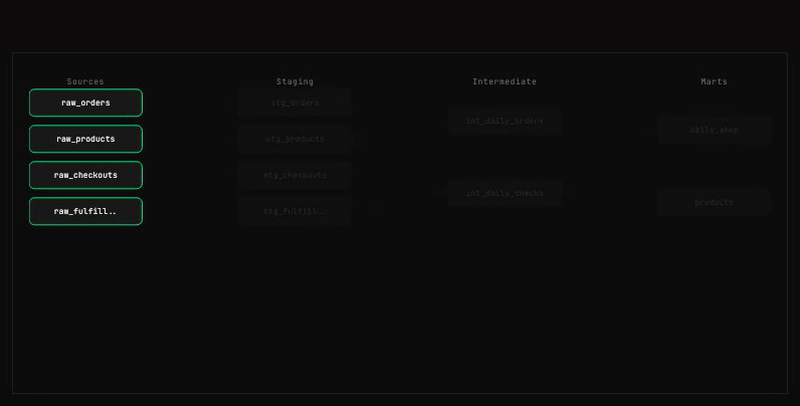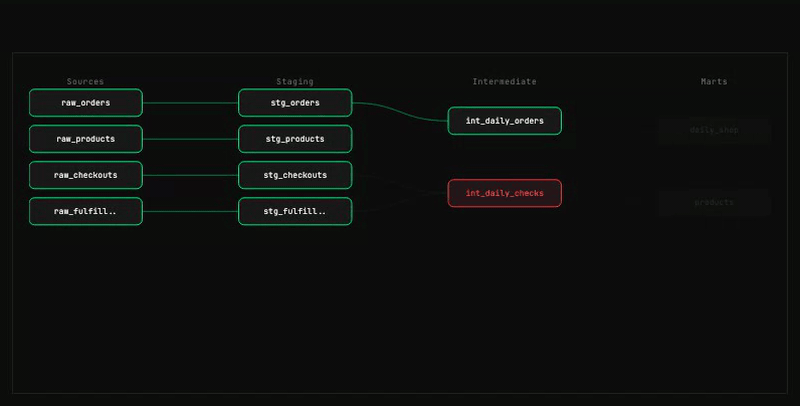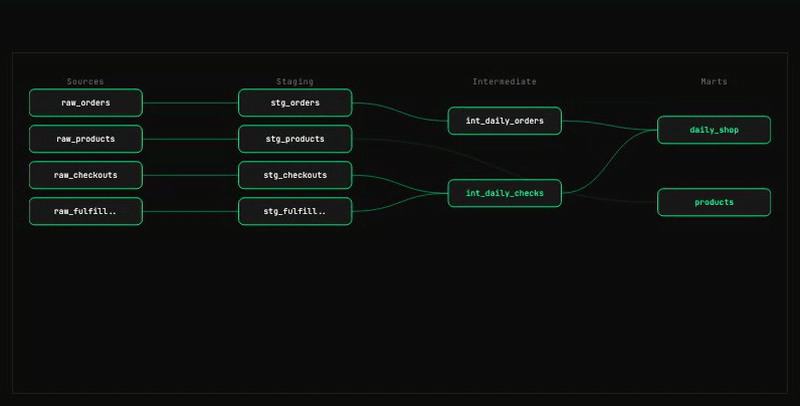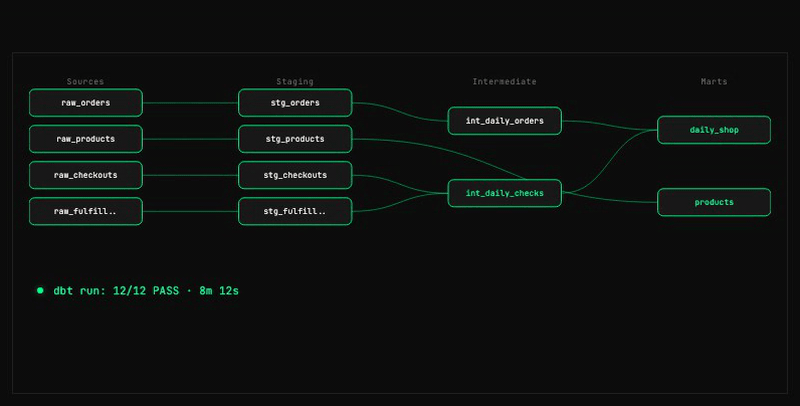
08 — Verify and fix

The agent dispatches two read-only verifier subagents in parallel via the Agent tool. Neither edits files, runs dbt, or modifies state — they return reports, and the main agent acts only on FAIL checks. Each is handed the project directory, connection name, model names, the domain skill name, and the path to technical_spec.md — but not column definitions or SQL logic, which the verifiers must discover themselves. A query_database SELECT 1 gates on gateway readiness first.
Structure verifier (subagent_type="verifier")
| Check | What it verifies | Tool |
|---|---|---|
| 1 — Table existence | Every model in models/*.yml is materialized | list_tables + Glob |
| 2 — Column completeness | All required columns present; YML names/types match | map-columns, check_model_schema |
| 3 — Row count / fan-out / cardinality | Row counts vs source, fan-out ratios, distinct counts, NULL fractions, grain | audit_model_sources (sample_nulls=true) |
| 4 — Non-deterministic SQL | No ROW_NUMBER/RANK without a deterministic ORDER BY in written SQL | Read |
| 5 — Source preservation | A modified model still reads from its original source table | git show + Read |
Fan-out is not automatically a defect: when duplicate lookup rows differ in any column (even a label variant), the fan-out is correct and Check 3 passes with a note. It fails only when duplicate rows are byte-identical across all columns.
Value verifier (subagent_type="value-verifier")
Loads the domain skill first (domain rules affect verification — e.g. whether returns are excluded), then runs three checks.
| Check | What it verifies | Tool |
|---|---|---|
| 1 — Sample spot-check | Sample values plausible and consistent with siblings | query_database |
| 2 — Aggregate cross-validation | Each metric matches its name's implied aggregation (total_X = COUNT(*), unique_X = COUNT(DISTINCT)) measured against real source data | verify_model_values (mandatory) + Read |
| 3 — Status filtering | Returns/cancellations/refunds excluded when the domain skill requires it | query_database |
Check 2 is the core value gate: verify_model_values returns COUNT(*) and COUNT(DISTINCT key) baselines for each candidate upstream. Manual aggregate queries are forbidden here — the tool's measured numbers drive the verdict, and a FAIL produces an exact CHANGE: <old expression> → <new expression> in <file> line <N> prescription.
The loop and stop condition
The main agent reads both reports and acts only on FAILs. For any fix it updates technical_spec.md first, rewrites the SQL from the updated spec, rebuilds (dbt run --select +<model> only on a missing-table FAIL), and re-dispatches both verifiers. The loop stops when both reports show every check PASS. At that point no model file is touched again — the verifiers are the final authority.
Query lifecycle (governed)
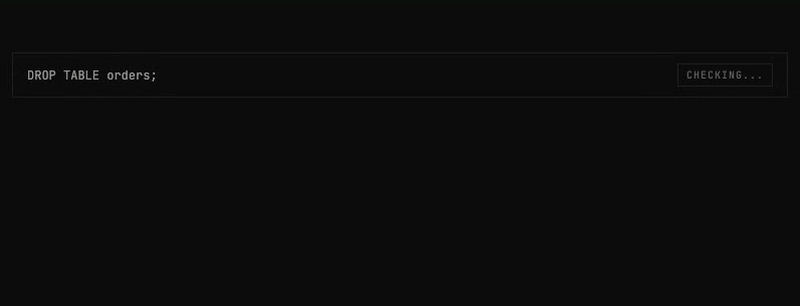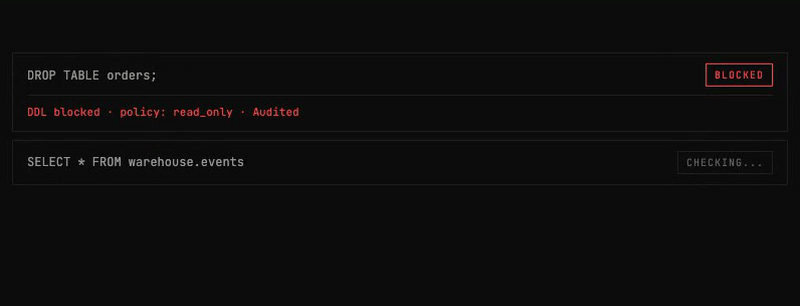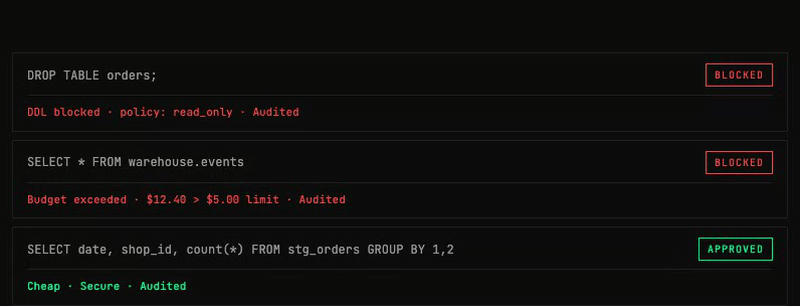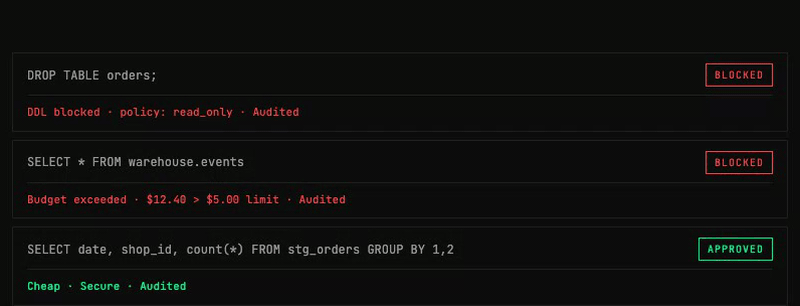
Every query_database call from any stage follows the same governed path:
Agent → MCP request → Gateway → SQL Governance → Database|Auth + Rate Limit|Audit Log (PII-redacted)
- Agent sends a tool call via MCP (e.g.
query_database) - Auth layer validates the API key or Clerk JWT, resolves the org/tenant
- Rate limiter checks per-key and per-org limits
- SQL governance parses the query: blocks DDL/DML, strips dangerous functions, injects LIMIT
- Engine executes against the target database
- Audit logs the query with SQL literals PII-redacted
- Response returned to the agent
Governance rules
- DDL/DML blocked: No
CREATE,DROP,ALTER,INSERT,UPDATE,DELETE - Dangerous functions blocked: 79+ functions across 7 SQL dialects (e.g.
pg_read_file,LOAD_FILE,xp_cmdshell) - LIMIT injection: Every SELECT gets a configurable max row limit (default: 1000)
- INTO clause blocked: Prevents
SELECT INTO/COPY TOexfiltration - Stacking prevented: Multi-statement queries are rejected
See Governance reference for the full rule set.